August 24th, 2008 · Comments Off on Why Don’t We Write Much About KM Strategies?

Since I began working in formal KM more than 10 years ago now, I’ve noticed a scarcity of writing about alternative KM strategies practitioners might consider. Strategies include a vision of goals and objectives and a high level plan for achieving them. In the early days of KM many practitioners simply viewed KM practice as an opportunity to build Best Practices databases. Later the action moved to Communities of Practice, and CoP projects were often viewed as the answer to the KM question. Next came an emphasis on portals and later a less intense emphasis on collaborative software. As my series on KM 2.0 is illustrating, now strategy seems to be to aim at enhancing knowledge sharing by implementing Web 2.0 technology in the enterprise.
From my point of view, all of the above seem to substitute decisions to implement either a technique or one or more software tools, for a strategy containing a vision, goals and objectives and a high-level plan. Thus, the question posed this blog is: “Why Don’t We Write Much About KM Strategies?” This suggests another question: “Why Don’t We Think Much About KM Strategies?”
Tags: KM 2.0 · Knowledge Management

I’ve been busier than usual for the past week and will be even busier for another week; so I have to postpone further work on my KM 2.0 series for awhile in favor of some posts that require less effort. This one will pose a question. Why don’t we see much impact modeling in Knowledge Management?
In past blogs, and various papers, I’ve characterized KM as the set of activities undertaken with the intention of enhancing knowledge processing, and I’ve also talked often about the three-tier model just below.

Both notions imply that KM activities have impacts on knowledge processing, knowledge outcomes, business processes (including the decisions and actions that comprise them), and business outcomes. Even if others view KM differently, everyone who practices KM assumes that KM activities have their effects, or at least combine with other things to have an effect. To put this another way, anyone who practices KM must assume a conception such as that illustrated below:

So when we plan KM interventions and when we evaluate results after the fact why aren’t we modeling impact? And as long as we’re not doing that, how can we expect to make the case that KM works?
Tags: KM Methodology · KM Techniques · Knowledge Integration · Knowledge Making · Knowledge Management
August 16th, 2008 · Comments Off on KM 2.0 and Knowledge Management: Part Six, The End of 2007 and Mike Murphy

There were two more highly interesting contributions to the discussion of KM 2.0 in 2007. The first of these was by Mike Murphy (CEO of InQuira), appeared in DM Review, and is entitled “Knowledge Management Revitalized.” The second was by Dave Pollard, appeared in his blog, “How to Save the World,” and is entitled “KM 0.0 – Simply Enabling Trusted Context-Rich Conversations Among Communities that Care.” This post will review Murphy’s contribution and the next, Dave Pollard’s.
One of the common themes we’ve seen thus far in earlier literature on KM 2.0 is a failure to be either be clear about a) what “knowledge” is, b) what “KM” is, and c) what the distinction is between “knowledge” and “information,” or alternatively to introduce definitions and distinctions which, to be kind about, are relatively easy to bring counter-examples against. This replays a major theme of earlier days in KM (see the critical reviews in Chapters 1-3 of my book with Mark McElroy), and is a very bad sign for those who hope that “KM 2.0” will be more successful than KM practice in earlier days, since I doubt that conceptual confusion about one’s fundamentals is a very good predictor of successful practice.
One can see this problem very clearly in Mike Murphy’s article. He begins by analyzing what was wrong with pre-KM 2.0 Knowledge Management. First, he points to the multiplicity of definitions of knowledge and KM, and asserts that some thought that knowledge is what is in documents and records, and others thought of knowledge as tacit personal knowledge in minds. So, for the first group KM became document management and records management, organizing information, and automating existing processes; and, for the second, it became getting employee input, which can get old very quickly, unless getting such input is continuous. Second, he also says that KM:
“. . . was also too rigid – older KM systems did not take into account that people were contributing content, so the content would naturally evolve as procedures and policies changed and employees moved roles. Without a flexible system, knowledge would become outdated quickly and rendered useless.”
This analysis of pre-KM 2.0 KM is something that may have been true in the days when Best Practices databases were popular during the 1990s. But since the late 1990s, I think very little of KM can be described in this way. The role of “people” in knowledge processing has been generally recognized in KM at least since 1995, and before then by individual writers going back to the very first writers who used the term KM, and content management systems certainly do make provisions for changes in content introduced by people. The split between those who believe that knowledge is codified and those who believe it is “tacit” or mental, is still present, of course. But, again, that split came into KM in very early days and still exists regardless of the introduction of Web 2.0 tools into KM. Moreover, the existence of a multiplicity of definitions of KM is also a problem that still exists, as a recent survey of definitions of KM by Ray Sims, makes all too clear.
More generally, I think Mike Murphy is illustrating a pattern that we have seen in the narrative of KM 2.0, before in this blog series. That is, in analyzing the difference between older KM and KM 2.0, there is a tendency to exaggerate differences by over simplifying and caricaturing KM as it existed earlier.
In analyzing the revitalization of KM, Murphy raises other questions about the validity of his views. One factor he cites in revitalization is that when KM started, RDBMSs and record-oriented content were the dominant forms of storage, and he states that with: “. . . the arrival of the Internet and its evolution leading up to today, unstructured data exists easily in so many forms that cannot be accommodated in an RDBMS.” While this is certainly true, KM has developed continuously along with the increasing use of the Internet. Portals and content management systems, and the application of search technology, have been strongly associated with KM, as have been community enabling support applications, all of which long-predated the advent of KM 2.0. KM 2.0 really has nothing to do with use of the Internet per se, but only with the development and increasing use of social computing tools in the last five years.
A second factor cited by Murphy is the aging workforce, the retirement of the baby boomers, and the resulting concern in organizations that valuable know-how will be walking out the door and cannot easily be replaced. While I agree that this is a factor in the revitalization of KM, and in the rise of the KM 2.0 meme, I also think it’s a factor in a generalized revitalization of KM, only partly connected to KM 2.0. That is, as a revitalization factor, this one is not specific to KM 2.0.
Murphy’s third factor in the revitalization of KM is increasing competition and the need for customers to deliver higher levels of customer self-service to compete successfully. This need, in turn, makes businesses more open to Web 2.0 tools that provide forums and other tools for exchange in which customers can participate. Again, this third factor, while consistent with the availability of Web 2.0 tools, and certainly driving their use is not specific to Web 2.0 since not all online forum tools are “Web 2.0” tools. Many are available using older portal technology.
Murphy next moved to explaining why things will be different for KM, this time around. The first thing he says about this is: “At the heart of it, KM is about enabling people to share information more freely so that they can be more effective doing their jobs.” And he’s seemingly oblivious that this idea about KM has been with us pretty much since the beginning of the field, and is perhaps a big reason why KM hasn’t had great success the first time around. That is, it’s highly debatable whether KM is primarily about enabling better information sharing. For one thing, sharing anything is only one aspect of KM, since it was widely recognized that enabling people to create new knowledge is also an aspect of KM, and, for another, even if KM is restricted to enabling sharing, it is knowledge sharing that it is supposed to enhance, not information sharing.
I think this characterization of Murphy’s about what is at the heart of KM is an indication of his casual and interchangeable use of the ideas of knowledge and information, and his failure to make a systematic distinction between them in characterizing KM 2.0. From the beginning of KM we have been beset by similar confusions, the final result of which is often that people who think this way, develop Information Management solutions which they then label as KM solutions. When these solutions fail to satisfy, the result is generally chalked up as another KM failure. The same will happen with KM 2.0, if we continue to perpetuate this confusion between KM 2.0 and what I will refer to as IM 2.0 (for Information Management 2.0).
Murphy’s reasons for thinking that things will be different with KM 2.0 include:
1) increasing competitive pressures motivate users to contribute to knowledge bases;
2) Greater need than before for a system that allows efficient information distribution across geographic regions of large companies and organizations;
3) The Web 2.0 movement reminds people that knowledge exists in many forms, while making it almost second nature for the “emerging Web 2.0 generation” to contribute content to knowledge bases, thus changing the way knowledge is collected.
4) KM 2.0 systems can constantly evolve when agents discover additional ways of solving problems and update the system, when users draft or recommend new content or changes to existing content, when users update personal profiles and preferences, when details from previous sessions are tracked by individuals, and when content is identified that users have not read yet, have already read, or that has been updated since the user has last read it.
5) KM 2.0 systems provide capabilities for customer feedback amending knowledge content, more effective Web self-service capability including customer tools to navigate the track record of information exchanges in discussion forums, internal users with privileges to click and recommend or contribute content from a forum topic easily capturing exchanges or aspects of them as “formal knowledge content,” and upgraded “. . . intelligent search mechanisms to categorize user intent and knowledge applicability,”
This is an interesting set of reasons for thinking that things will be different this time. However, reasons 1) and 2) seem a bit abstract and also not unique at all to the Web 2.0 period. Reason 3) seems less than compelling also, because people hardly need reminding that knowledge comes in many forms, and also because I doubt that the motivation of the “emerging Web 2.0 generation” to contribute content to organizational knowledge bases can be taken as a powerful enough influence to contribute materially to the success of KM. Perhaps this reaction is too cynical, but if KM practice has learned anything in earlier years it is that people are motivated by their work dynamics. If these dynamics produce a need to contribute content to organizational knowledge bases, then they will do so. Otherwise, the motivation of this emerging generation will not suffice to ensure continuous contributions to knowledge bases.
When we move to the reasons under 4) and 5) I think Mike Murphy is on firmer ground. IT capabilities are much greater currently for enabling the production and sharing of information and also knowledge content, for collaboration, and for searching and retrieving the record of people-to-people exchanges. Introducing Web 2.0 into organizations will certainly lead to a greater volume and intensity of information sharing, at least to begin with. However, I also think that many of these capabilities are pre-Web 2.0 innovations and that neither they, nor the Web 2.0 innovations, provide sufficient reasons to think that things will be different this time.
The reason for my doubts about this, are reflected in Mike Murphy’s approach to the KM 2.0 discussion, and my disagreement with it. His article leaves no doubt that he thinks that KM 2.0 is KM that uses Web 2.0 tools to enable information sharing. To the extent that this orientation is shared by others who advocate KM 2.0, or, even worse, to the extent that KM 2.0 gets defined this way, there will be no clear idea of the relation of KM as a social activity to knowledge processing broadly defined as problem seeking, recognition, and formulation, knowledge making (knowledge production, creation, discovery), and knowledge integration (knowledge and information broadcasting, searching and retrieving, teaching, and sharing), and then, in turn, no clear idea about the relationship of the introduction of Web 2.0 tools to enhanced knowledge processing.
In particular, as I’ve pointed out elsewhere, the fulcrum of knowledge processing, that distinguishes it from information processing, is knowledge claim evaluation (or error elimination, if you prefer). One thing we need to know when evaluating the new Web 2.0 software tools, and whether their appearance really does signify the coming of KM 2.0, is whether, and in what way, those tools enhance knowledge claim evaluation. The reason why this is vitally important is because if these tools have little or nothing to contribute to this knowledge sub-process or its management, then, in the end they are nothing but IT tools after all, because, even if they help us in sharing information and in collaboration, they help us not at all in classifying knowledge claims into those that are false, those that are undecided, and those that have survived our criticisms tests, and evaluations. Thus, they also help us not at all in increasing the quality of our knowledge, and in increasing the quality of our decisions which rely on that knowledge.
In short, Mike Murphy’s article advocates the position that KM 2.0 is enabling enhanced information sharing with Web 2.0 tools, and also that KM 2.0 will be successful for a variety of reasons amounting to the assertion that these tools will enhance information sharing. There is not much wrong with this argument as long as one accepts that KM is about enhancing information sharing. But, again, while that may be a vision for Information management; it is not and never has been a vision for Knowledge Management, except perhaps in the early days aphorism saying that KM is “getting the right information to the right people at the right time.” In First Generation KM, however, the dominant vision throughout the 1990s was KM for enhanced knowledge sharing, and in Second Generation KM up to the present, it is enhanced knowledge production and enhanced knowledge sharing. Finally, in the New Knowledge Management, my own orientation, the strategic vision is to gradually enhance knowledge processing in the organization in a manner that will add increasing value and create sustainable innovation over time. So, none of the last three orientations would accept the idea of KM 2.0 as a discipline devoted to enhancing information sharing through the use of Web 2.0 tools. On the other hand, Mike Murphy has failed to show that the introduction of Web 2.0 tools enhance knowledge sharing , or both knowledge making and knowledge integration, or enhance these things in a sustainable fashion.
To Be Continued
Tags: Epistemology/Ontology/Value Theory · KM 2.0 · KM Software Tools · Knowledge Integration · Knowledge Making · Knowledge Management
August 14th, 2008 · Comments Off on KM 2.0 and Knowledge Management: Part Five, More on Dave Snowden’s Take

4) Another important point made by Dave in the podcast is that those looking to create a knowledge sharing culture are thinking about knowledge sharing from the wrong perspective. The problem is not to create such a culture, but rather to increase the connectivity of people, whereupon they will naturally share because the increased connectivity increases “the immediacy of KM requests.” Moreover, this sharing will happen without using explicit incentives, which don’t work anyway. In relation to this formulation, I very much agree with Dave on some, but not all of its aspects.
I agree that those looking to create a knowledge sharing culture are thinking about this issue from the wrong perspective. I think the right perspective is to focus on changing behavior in such a way that the changes are consistent with existing cultural norms, while the changed behavior is such that it creates great pressure for changes in culture to co-evolve along with increasing changes in behavior. Further, I agree with Dave that incentives don’t work in getting people to share. I also agree that the way to change behavior is to enable greater connectivity, which will give people the opportunity to naturally share. I disagree, however, that increased connectivity will necessarily be followed by a stable increase in the level and quality of knowledge sharing, since there is a considerable possibility that increased connectivity will lead to conflict, mistrust, and eventually a decline in sharing. Which way things will go, depends in part on the social context of the introduction of Web 2.0 tools, as well as on how people work through that social context to collaborate in a cooperative way. Finally, Dave refers to KM requests for knowledge sharing. However, even though there may be some of those, requests for knowledge sharing most frequently come from people who are looking for and who may need help, and therefore they are primarily knowledge processing rather than KM requests.
5) In developing his view of the Impact of Web 2.0 tools on KM, Dave draws the conclusion that the use of such tools would lead to a situation in which there would be no management of knowledge sharing. That is, there would be no formal KM roles, but that “knowledge work is just the way we do things around here.” It would not be managed at all.
This view, of course, is based on an interpretation of complexity theory suggesting that the self-organization of knowledge sharing activities enabled by using Web 2.0 tools would result in stable and beneficial knowledge sharing in an enterprise that, in turn, would remove the need for formal KM activities. I don’t agree with this line of reasoning. I think the tools do enable self-organization in knowledge sharing and that the resulting patterns may well be beneficial. However, I don’t believe in permanently effective and stable “invisible hands” in human CASs, especially when humans participating in CASs may want to manipulate knowledge sharing patterns to their own advantage.
Moreover, Web 2.0 tools are only one wave of technology. The next wave, probably focusing on applications using intelligent agents, will present us with new possibilities and also new possible interventions for enhancing various aspects of knowledge life cycles, including knowledge sharing. Still further, KM is not concerned with enhancing knowledge sharing alone, but also with problem seeking, recognition, and formulation, and with knowledge production. While Web 2.0 tools impact these areas as well, I don’t think their impact on self-organization, distributed cognition, and enhanced functioning in these areas is as clear as their impact on knowledge sharing.
Yet another reason why KM won’t disappear as a result of success with Web 2.0, is that the (KM) goal of enhancing knowledge processes is an open-ended one. Even if the introduction of Web 2.0 proves to be a success for KM in knowledge sharing, that won’t make formal KM disappear because the need for formal KM will be gone, Instead, it will merely emphasize that KM can be successful given the right conditions. That will only whet the appetite for formal KM activities and will serve to increase the credibility of KM practitioners.
6) Jon Husband also asked Dave about the impact that Web 2.0 tools are likely to have on the idea and practice of knowledge audits of knowledge assets. Dave answered by saying that such audits implied that knowledge was static and a thing, and that most effective knowledge exists in flows, and is contextually created in a time of need, and he provided the previous line I quoted above about knowledge being a “. . . real time assembly of multiple fragmented memories . . .” He then went on to say a) that a problem with knowledge audits is that “you can’t audit fragments.” b) Web 2.0 results are too unstructured to view them as knowledge assets in themselves. You can do a lot with wikis. But the issue with blogs is that you need a way to recall blogs that are some years old. c) A big “issue is categories and keywords,” and tagging. Blogs can be viewed as narratives that create a semi-structured system, and Cognitive Edge is doing this in some of its work. But to do this well, you need some type of common tagging system in each enterprise, and that system has to handle text, pictures, and you tubes. d) In creating that kind of system, we’re asking people to create levels of meaning for objects like blogs and narratives by human-based tagging. Keywords one associates with a blog or a story may not be in the story, human-based tagging is the key to creating additional levels of meaning. It is not just the text that counts in blogs; it is the context of their creation including the people links.
Dave and I have an ongoing disagreement about the issues of whether knowledge is a thing, or both a thing and a flow. The latest installment of this disagreement is in this post. Here, I don’t need to review that. I did like Dave’s emphasis on how knowledge is created in context and in response to need and also his criticism of knowledge audits which, I too, have objected to for two reasons. First, because lacking a basis for distinguishing between information and knowledge in the hands of KM practitioners they are really information audits, and second, because from my point of view, a) knowledge audits can’t tell you where knowledge gaps are, because such gaps are discovered in specific contexts where problems are arising in instrumental activity, while “knowledge audits” are an abstracted activity that catalogs knowledge claim object holdings, without reference to problem contexts, and b) audits of knowledge asset holdings are not nearly so significant for KM as audits of various sub-processes of the knowledge life cycle and how well they are performed in various business domains in the organization.
But apart from our agreement on the very limited value of knowledge audits, I was also very pleased to see Dave’s emphasis on the importance of generating categories and tags, of the problems of creating common tagging systems, and of the importance of doing this because of the need to create additional levels of meaning for texts and text fragments, to express the richness of context. In some of my earlier work, I’ve emphasized that cultural knowledge is comprised not only of knowledge claims that have survived our criticisms, tests, and evaluations; but also meta-claims about these, recording the performance track record of such claims. While I know that Dave did not have knowledge claim evaluation or error elimination in mind when he talked of placing additional levels of meaning on fragments in Web 2.0 contexts, I’m quite excited about the potential for such human-based tagging to begin to record such track records in the course of adding additional levels of meaning to text.
7) In discussing the problem of merging more traditional sources with Web 2.0 creations, Dave makes the very good point that what matters is “creating a map of the dependency of core business processes on knowledge objects.” He then points out that knowledge objects need to be indexed, clustered, and connected to decisions, and that coherent clusters need to created that can then be managed. He also points out that this is a “bottom-up” design. Jon Husband commented that this approach ‘tracked well” to the use of tags and asked whether that was the same as “bottom-up?” To which Dave replied, that it is similar, but that one needs to put some structure on tagging so that people will use tags in the same way.
I like this way of putting things very much. For business process analysis and management, I think this is a very good view of things, and for knowledge asset audits this is also a way of looking at things that is very useful. Such a map is also a very good construct for sharing knowledge, since it places knowledge objects in the context of their use in business process activity and decision making. Finally, it’s also a very good framework for taking a functional view of both Web 2.0 and older sources in a common context.
8) To end the interview, Jon elicited Dave’s ideas about what will happen to KM in the context of the spread of Web 2.0. Dave’s view is that the KM function will become more important, while at the same time, formal KM will disappear. This will happen in the context of the collapse of the dominance of IT in the enterprise. IT departments will need to place more security around data and content, but reduce security on collaboration to a minimum.
I didn’t find Dave’s reasoning in this part of the interview to be very cogent. Specifically, the connections between the various parts of his view of what will happen are not very clear to me. Perhaps he thinks that the decentralizing and self-organizing effects of social computing will undermine both centralized IT and the formal version of KM which has made use of applications that have been enabled by centralized IT. If this is right, then it might follow that both centralized IT and KM will both decline as Web 2.0 continues to spread. However, I don’t think this line of reasoning works.
For one thing, I don’t think centralized IT is collapsing, since Service-Oriented Architecture (SOA) seems to be giving it a boost right now, which will take at least a few years to subside. For another, I don’t think that formal KM is really linked to the centralized IT function, or that it is focused entirely on knowledge sharing. Nor do I believe that the success of self-organization and distributed cognition in the enterprise removes the need for formal KM. As long as formal KM supports self-organization and distributed cognition it can flourish in a Web 2.0 environment, and especially in a Web 2.0 environment characterized by SOA and mash-ups.
Finally, it is interesting that Dave’s take on Web 2.0’s impact on KM is not heavily oriented toward claims that there is a KM 2.0. Many associated with the KM 2.0 meme, including Jon Husband, John Tropea, and Luis Suarez, apparently view Dave’s interview as supporting the idea that there is a KM 2.0. But I think that Dave himself, views the impact of Web 2.0 as leading to the death of formal KM, by removing its rationale. Perhaps this difference is just semantics. But somehow, I don’t think so. Dave has never viewed generations or ages of KM as defined by changes in technology. Instead he has contended that change is a function of change in the conceptual point of view characteristic of KM. However, I think supporters of the idea of KM 2.0 seem to be taken with a certain technological determinism and seem to think that a fundamental change in KM was at hand when Web 2.0 tools began to move into the enterprise. For myself, even though I don’t agree with Dave’s specific view of the conceptual change that defines a new generation of KM, I certainly agree with him that the issue here is conceptual, and not technological. The fundamental point is that KM is a human activity and not a class of software tools. Such tools are only enablers for KM practice. As such, changes in software tools that have implications for more successfully enabling certain areas of KM practice are very significant. But much more fundamental change in KM is the sort of change that expands the very scope of activities that we identify as KM. In the period before 1995, KM was mostly focused on sharing knowledge that was assumed to exist. But during the period from 1995-2000, it became increasingly well recognized that KM was also about enabling knowledge production in various ways. This was a fundamental change in KM, because it identified KM with innovation and organizational learning and not simply with spreading existing knowledge around. This fundamental change in KM is still in “early days,” because its implementation still has a long way to go. It is the real KM 2.0. Changes in conceptual orientation from top down KM to complexity, and changes in KM from Web 1.0 to Web 2.0 tools are very important, but they don’t add anything new to the scope of KM, and it is that scope that is the true fundamental dimension of the field. I’ll return to this theme in future posts, as I finish discussing the progress of the KM 2.0 debate in the remainder of 2007 and in 2008 up to the present.
To be Continued
Tags: Complexity · Epistemology/Ontology/Value Theory · KM 2.0 · KM Software Tools · Knowledge Integration · Knowledge Making · Knowledge Management
August 13th, 2008 · Comments Off on KM 2.0 and Knowledge Management: Part Four, Dave Snowden, Complexity, and the Impact of Web 2.0

The next major contribution to the KM 2.0 discussion comes in an interview of Dave Snowden by Jon Husband entitled “The Impact of Web 2.0 on Knowledge Work and Knowledge Management.” The interview was done on October 15, 2007, and then produced and distributed as a podcast.
This podcast was followed by many reactions in the blogosphere over a period of months. In general, the blogosphere comments, are laudatory and either summarize the podcast (See Luis Suarez’s contribution on November 23), or comment on it in a general way (See John Tropea’s on November 28). I may have missed something, but thus far, I haven’t seen very much specific value-added commentary on the views expressed by Dave in the podcast, anywhere. So, I’d like to offer an analysis of some of his statements in my next two blog posts.
1) Dave states that the social computing tools constituting Web 2.0 “effectively self-assemble, self-organise and deal with informal connectivity learning” in contrast to earlier tools which were about structuring data and content. It is correct, of course, to say that Web 2.0 tools are focused on “connectivity,” though I’m not sure what the phrase “connectivity learning” is meant to convey. It is also true that their use enables self-organization. However, I don’t think that what Dave means by the tools self-assembling and self-organizing is very clear. The people using the tools may self-organize through their use, but I don’t think the tools by themselves do any of the self-organizing.
Nevertheless, as Dave says, the important point here is that social computing tools are about people voluntarily linking to one another and creating newly self-organized networks. And it is clear, I think, that such tools present new possibilities for collaboration that do not exist without them. However, it’s also true that tools facilitating linking and more intense social interaction also create new possibilities for conflict that did not exist before. It is probably wise to keep this in mind when looking at Web 2.0 tools, as well.
2) Next, Dave emphasizes heavily the role of context in knowledge sharing and the idea that older tools assume “context independence.” He also, correctly points out that “context” is very important to get people to share their knowledge. He ties ‘context” very compellingly to knowledge when he says that “we only know what we know when we need to know it,” and when he also says that “human knowledge is the real-time assembly of multiple fragmented memories in a real-time context to create a new application.”
Dave’s written about “context” and its importance for some time now, in many different blog posts and publications. But I must confess that I’m still not clear about what he means by the term. Of course, I have my own view of context, and it’s represented graphically just below.
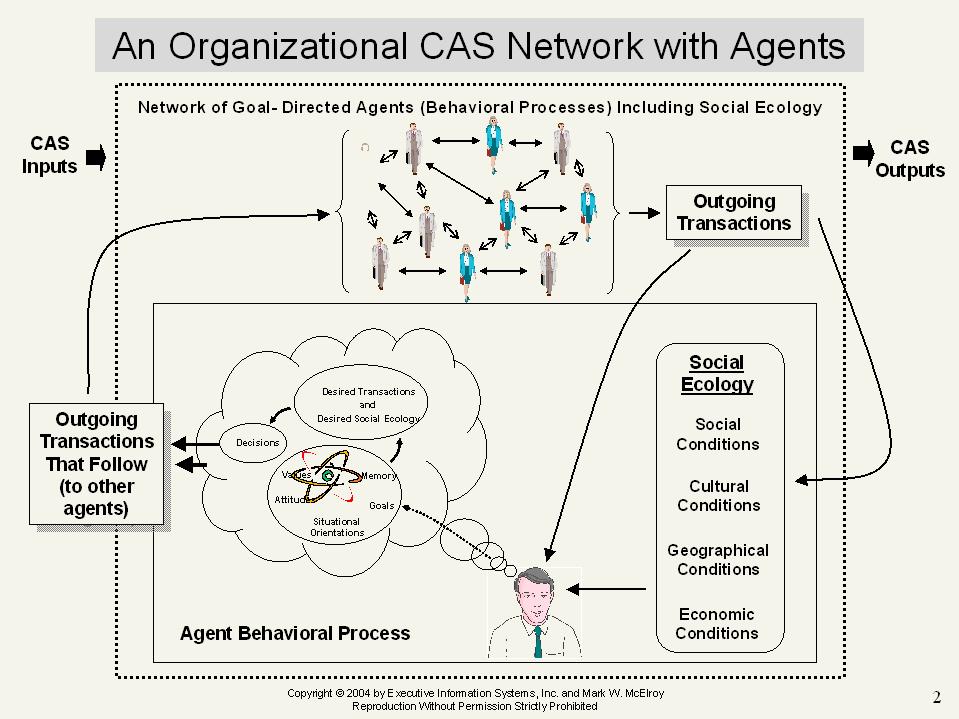
In that graphic, the active agent, the decision maker, has a context of action. You can see all the influences of context on the agent’s decisions. And you can see that the agent’s decisions feed into, and are part of the social network that is the CAS within which the agent acts, and that also is the primary context of its action.
Now, let’s assume that Dave’s view of “context” and my own are not that far apart. Then, when he says ““human knowledge is the real-time assembly of multiple fragmented memories in a real-time context to create a new application,” he probably means that the human as a system actively interprets the context by assembling memory fragments to construct knowledge in context, and if this is so, it is certainly very consistent with the graphic I’ve presented. But is that all that knowledge is? Is it only the situational orientation that our systems construct in the course of our interacting with context?
If so, then I think this view is too simple. Here, I’ve given a view of knowledge suggesting that there are three kinds of knowledge: biological knowledge, mental knowledge, and cultural knowledge. I know that Dave doesn’t accept my semantics here. But regardless of the semantics, situational orientation/knowledge that we construct by assembling memory fragments and other elements exists. Whether we include it in a category called ‘mental knowledge,” or use some other label is of little importance. Further, even if one doesn’t accept that cultural objects, and biological synaptic structures and DNA are forms of knowledge, the idea of “mental knowledge,“ raises some questions? For example, are our situational orientations, the result of our assembling memory fragments, all knowledge. Or are some aspects of them just belief, and not knowledge? Are emotional orientations knowledge? Are purposes knowledge? Are intentions knowledge? All of these questions are relevant because all of these seem, in some way, to follow on our assembling memory fragments in context.
Also, the idea that there is mental knowledge, also raises the question of whether there is more to such knowledge than just situational orientations or some aspect of them. In particular what about “tacit knowledge” or “implicit knowledge”? And what about “knowledge predispositions”? Are these just what we assemble from our memory fragments? How can this be, since predispositions are not assembled from memory fragments in context. Yet surely they exist, since more than a century of psychological research says that they do, and also, that they exist in addition to, and alongside of, our memory fragments. The graphic just below suggests that what we assemble in context from our memory fragments is only one aspect of our knowledge, only our “explicit knowledge” in the mind. It is that sort of knowledge of which we can say: “we only know what we know when we need to know it.”
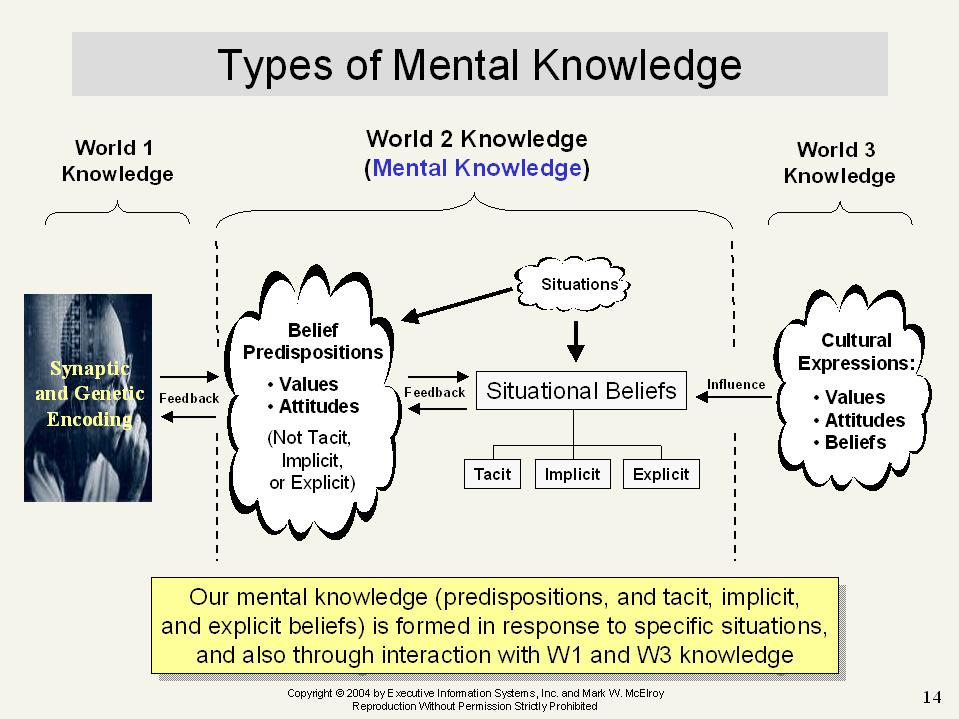
3) Dave also said that the immediate context is very important to get people to share their knowledge. I think he is right about this, and that we can also see it if we reflect on the remarks I’ve just made about our respective views of knowledge. From my point of view, first, we clearly can’t share biological knowledge directly, whatever the context. Second, however, we can share our cultural knowledge, and we do so by creating it in our expressions of what we think, and by exposing those creations to others. But how do we do that? The answer is that we assemble our memory fragments in context, and then proceed to create our cultural knowledge by using what we’ve assembled in expressing ourselves. Third, can we share what we assemble from our memory fragments, i.e. our psychological situational orientations? The answer is no. These beliefs, whether knowledge or not, cannot be shared directly because we are not telepaths. They can only be expressed in cultural form, whether in language, graphics and art, music, and other cultural expressions, and then made available to others.
So, when Dave says the immediate context is very important to get people to share their knowledge, I think he is right, and he is right because people express themselves and create cultural knowledge in context. Without context, no cultural knowledge can be produced, and if none is produced then none can be shared.
But having said all this, it raises some important questions which I don’t think Dave has dealt with. Thus, fourth, if we look at the two figures again, we can see that all our knowledge is produced “in context,” and, not only that, but all our actions are performed in context as well. So, there is no way to produce knowledge outside of some immediate context or other, or for that matter to share it or refuse to share it outside of some context. Since there is no way to either make or share knowledge outside of some context, what does it mean to say that immediate context is necessary to get people to share their knowledge?
I think it means that different contexts produce different kinds of knowledge and varying predispositions to share it, and that certain situational contexts lead to producing and/or sharing cultural knowledge that isn’t very relevant to decision contexts, while certain other situational contexts are better for producing and/or sharing cultural knowledge that is more relevant to action contexts we are interested in.
For example, survey research contexts produce cultural expressions from people that may express aspects of their knowledge, but these aspects are not, in general, highly relevant to any problems businesses or organizations face, because the contexts of generation and sharing of survey research knowledge are not sufficiently similar to the contexts of everyday decision making or learning to make the knowledge shared in survey responses very useful. In addition, in survey research contexts, respondents don’t have very much control over what and how they will share. Questions are presented to them that assume a particular framework that they may not either share, understand, or approve of. Their response choices are often frequently restricted and are also in a framework that is not their own.
Further, when people in organizations worry about “capturing knowledge” of those who are retiring or leaving for parts known or unknown, what they want is to somehow transfer the very relevant “how to” knowledge of the retiring individuals to other individuals who aren’t retiring or leaving. However, this “how to” knowledge is, as implied by Dave’s expression, assembled by people as they perform tasks in context. Such knowledge can’t be expressed in language in a sufficiently detailed way for people to use the results of interviews or other structured language products elicited in artificial inquiry sessions to reproduce the same or functionally equivalent “how to” knowledge in themselves.
On the other hand, when people express themselves in blogs and wikis, in collaborative content tagging, in folksonomies, in digital videos and podcasts, in social bookmarking and in virtual environments, in problem solving communities and collaborative teams supported by web 2.0 software, and using mashups to move across a gamut of applications to express themselves, then the contexts of expression are either much more like natural work contexts or, alternatively are even work contexts that have been re-invented anew using the new tools. Also, what and how people will share in these contexts are more influenced by their own perceptions, understandings, frameworks, and choices. There is a certain freedom in their sharing activities that does not arise in survey or other structured inquiry contexts.
So, the argument in favor of Web 2.0 tools here, should not be that some (specifically Web 2.0) knowledge is generated and shared in contexts following the assembly of memory fragments, while other types of knowledge (associated with older tools) is shared successfully because it is out of context, but rather that the contexts associated with the use of Web 2.0 tools are much more closely associated with the creation and sharing of knowledge that is meaningful in problem solving and decision making contexts.
And another very important point about context, which is made explicitly by Dave in the interview, is that older tools, in the way they produce data and content, seem to assume, erroneously, that the knowledge that is produced, and then shared, is context independent. So, when that data and content is stored, it is routinely stripped of the context in which it was generated, which is necessary both for its interpretation and understanding in knowledge sharing. In contrast, however, the knowledge produced and shared through using Web 2.0 tools is often shared along with much more of the context that generated it, then the “knowledge” shared using the older tools. Therefore, Web 2.0 shared knowledge is much easier to interpret and understand, than “knowledge” shared through the use of tools that share much less of the social and cultural context of knowledge production, and, as a result, knowledge sharing can be much more successful than it was before.
To be continued in Part 5
Tags: Complexity · Epistemology/Ontology/Value Theory · KM 2.0 · KM Software Tools · Knowledge Integration · Knowledge Making · Knowledge Management · Personal KM

To foster openness in an adaptive team, try to create a culture where team members internalize the following norms, collectively known as the Sustainability Code, developed by Mark McElroy and I a few years ago for our CKIM Workshop. Here’s the code:
1. All knowledge used as a basis for individual and/or shared action by members in a collective – in the context of the collective – shall always be open to criticism, and no such knowledge shall ever be regarded by any member as true with certainty. This is the FALLIBILITY rule.
2. All organizational knowledge in the collective shall be accessible and transparent to all members, regardless of management roles or structures in place. No such knowledge shall be withheld from a member of the collective by any other member, except in cases where fulfilling fiduciary duties or the need to respect privacy entitlements are involved. This is the TRANSPARENCY rule.
3. All learning and innovation processes in the collective shall be accessible to, and inclusive of, all members, regardless of whatever separate and/or restricted management roles or structures may be in place. This is the INCLUSIVENESS rule.
4. All learning and innovation in the collective shall be rooted in the principle of fair critical comparison, such that prevailing or competing knowledge claims may always be criticized, tested and evaluated against one another in a fair and complete way. This rule shall apply to claims of what such tests themselves should consist of, and not just to the primary claims to which such tests may be applied. This is the FAIR COMPARISON rule.
5. All members of the collective shall employ their best efforts to seek, recognize, and formulate problems in existing knowledge through critical evaluation of the performance of that knowledge in action. This is the LOOKING FOR TROUBLE rule.
6. The actual or potential performance of knowledge in action shall be defined to include the social and environmental impacts of actions taken, and in particular the sustainability of such impacts. No such impacts shall arbitrarily be externalized or otherwise excluded from the scope of evaluations performed under rules number 4 and 5 above, and all such impacts determined to be unsustainable shall be internally assessed accordingly, in related evaluations. This is the INTERNALIZATION rule.
7. Members of the collective may produce any new rule not otherwise specified by these rules, so long as it and the learning system used to produce it do not contravene these rules. This is the GROWTH OF KNOWLEDGE rule.
8. Rule numbers 1 through 7 shall apply to not only knowledge claims of fact, but also to knowledge claims of value as well. This is the FACT/VALUE rule.
9. The collective shall establish a Knowledge Management function that will be independent of the Executive Function and invested with enforceable authority to:
(1) allocate resources for enhancing all learning and innovation in the collective,
(2) change and enhance all knowledge processing rules,
(3) handle crises in knowledge processing, and
(4) negotiate for resources with other organizational functions.
10. The Knowledge Management function shall adopt and implement only knowledge processing policies that are aligned or synchronized with the self-organizing tendencies of people in organizations to produce and integrate knowledge as they will. This is the POLICY SYNCHRONIZATION rule.
11. Any member who fails to abide by these rules shall be subject to exclusion from the collective by its other members, at their discretion. This is the ENFORCEMENT rule.
We intended to apply the Sustainability Code to organizations, but I think there’s no reason why it shouldn’t be applied to teams, and other organizational sub-systems, as well.
The code incorporates within it a model of “rational” decision making (RDM) in innovation, which envisions posing and assessing alternative decision models through fair critical comparison. However, it would NOT be rational to apply this part of the Code to teams operating in situations where the decision time is severely restricted, and therefore measured consideration of alternatives isn’t practical, and yet innovation is still necessary. In particular, fair critical comparison may have to be severely restricted because of time constraints, and it may be necessary to operate in a way that emphasizes sequential trial and error more heavily. In situations like this, Recognition Primed Decision Making (RPD) should replace RDM in adaptive teams. I’ve explained the relationship of RDM and RPD here, and also explained (a) why there isn’t only one rational decision making pattern, and (b) why so-called RDM isn’t always rational.
Tags: Complexity · Epistemology/Ontology/Value Theory · KM Techniques · Knowledge Integration · Knowledge Making · Knowledge Management

In a recent discussion in actkm over the past few days, Steve Denning raised the question of how one might create “high performance teams.” In this and the next post, I’ll provide a slightly revised version of one of my replies during the discussion.
Unless high performance teams are performing routine business process work using knowledge that works, they can’t be “high performance” without having the ability to adapt to challenges. That entails having the ability to seek, recognize and formulate problems, solve them, and integrate the solutions either within the team or the larger enterprise. A team may develop that ability without recourse to knowledge management. But if management deliberately sets out to create teams with such a capacity, then, I think that for better or worse they are doing KM.
Steve raised the question of how high performance teams are created. I think that teams constituted to do routine work should be comprised of individuals selected for their ability to perform their appointed tasks within the team, and also for their ability to collaborate with others. On the other hand, if we’re talking about putting together teams that will develop adaptive capacity (i.e., the capacity for innovation), then I think we have to worry about both constituting the team in such a way, and managing it in such a way, that a culture of openness is fostered.
Constitution of a team that will excel in problem solving may require a sustained effort to recruit people who have a track record of previous successful problem solving. One principle to follow is Ashby’s. That is, recruit people who collectively are likely to provide the team with the greatest amount of variety in new ideas. A second principle comes from Popper. Recruit people who are likely to provide the severest critical evaluation of new ideas. A third principle also comes from Popper. Recruit people who are good at critical exchanges in the sense that they can both criticize the ideas of others and receive criticism of their ideas without getting personal, and with the ability to recognize when an idea they love hasn’t performed very well.
More generally, people with high risk intelligence may be recruited for the team. I’ll explain what I mean by that in the following paragraphs quoted from an adaptive metrics center report on Relative Risk Intelligence Metrics:
“The application context for organizations
Consider the situation of the manager who is tasked with recruiting a team to meet a particular organizational challenge. The very notion of an organizational challenge implies that a problem area exists and that learning followed by decisions will be non-routine and must be creative. Task forces and teams are about problem solving, and the solutions to be developed risk error and its consequences. It is therefore in the manager’s best interests to staff his/her task force or team with knowledge workers who have a high level of relative risk intelligence in the problem area involved.
“The manager will often be faced with multiple possibilities in recruiting members of the team. Unlike the context of competing organizations entering a new area and the selection of one of them as the highest in risk intelligence, in a large organization, there may be 30 – 50 or more possibilities from which to choose 4 – 6 or more team members. While many aspects of a test for relative risk intelligence may be the same or similar to the test for relative risk intelligence of competing organizations, there will also be critical differences in this area of risk intelligence testing.
“The test
Test factors
Once again, the key to measuring relative risk intelligence is the realization that it can be closely identified with the ability, in this case of an individual team member, to perform creative learning in the problem (i.e. business) area being targeted by the team and integrate the results of creative learning into the distributed organizational knowledge base that supports decision making and action. This leads, based on similar theoretical considerations to those used earlier to a five factor test of relative risk intelligence. The sixth factor, the ability of individuals and groups to learn, is not relevant because this test is focused on the individual level of analysis.
“Here are the five factors along with brief comments on each.
1. How does the individual being rated compare to other individuals in her/his ability to seek out, recognize and formulate problems in the team’s knowledge of the risk area? This is important because, once more, you can’t solve a problem, if you can’t see that you have one. So, the ability to perform the activities described in this factor is critical to the ability to learn about risks and reduce the risk of error in your solutions.
“2. How does the individual being rated compare to others in ability to acquire information (including experience) that is relevant to helping to develop new ideas about how to solve problems in understanding the risk area? Acquiring information from external sources that we evaluate as solving our problems is often less expensive in time, resources, and effort, than figuring out the solution to a problem ourselves.
“3. How does the individual being rated compare to others in ability to formulate new ideas or solutions in the risk area? This is about coming up with new ideas, a dimension that’s essential to problem solving, and to arriving at alternative models that can help in reducing the risk of error. An important factor is the attitude of the individual to new ideas and how they ought to be introduced. Some individuals are mistrustful and even hostile to new ideas, both ideas of their own, and especially, those of others. They tend to want to cut short discussions developing new ideas. They also may restrict themselves in the range of methods they use to develop new ideas. The ability to develop new ideas is critical for the team’s effectiveness in distributed problem solving, because it is an important factor in producing the necessary variety of new solutions the team needs to evaluate to arrive at effective solutions to its problems.
“4. How does the individual being rated compare to others in ability to criticize, test and evaluate the new ideas it formulates to solve problems in its targeted risk area? This dimension is about the ability to eliminate errors through fair comparison. Again, I explain what fair comparison is in Appendix 3. Without it, an individual’s evaluation of competing alternative solutions will be biased against arriving at solutions to problems that work and that are more likely to be true than the solution’s competitors. Fair comparison is what allows us to select solutions that carry with them the minimum risk of error. If an individual can’t do this better than other possible team members, he/she will be less capable than others of learning about risks in a way that minimizes the risk of error.
“5. How does the individual being rated compare to others in her/his ability to integrate (i.e. broadcast, make available in searchable sources, share, and teach) the solutions to problems the individual or the team develops? This dimension is about an individual’s ability to integrate new knowledge once creative learning produces it. The ability to keep records is very important here. But the individual’s capabilities to search, share, teach and broadcast are even more important.”
The report provides a method for developing RRI ratio scores for candidate team members based on the Analytic Hierarchy Process. In Part Two, I’ll move to the question of developing an adaptive team, once people are recruited for it.
Tags: Complexity · KM Techniques · Knowledge Integration · Knowledge Making · Knowledge Management
August 8th, 2008 · Comments Off on The Second Theme: Clear Definitions of KM and KCE, and “Complexity Science”

My last post commented on Dave Snowden’s primary argument against a National KM Center, discussed in “Emperor’s Chess Board: Pt. 1” and “The Empire Repeats.” In addition to this argument, however, in “The Empire Repeats,” he wrote of two themes that emerged in the actkm discussion on National KM Centers and “connecting the dots.” The first theme, that this time we will get KM right, he discusses in the blog. But of the second theme he says:
“The scary idea that any approach needs clear definitions of knowledge management, and criteria by which various claims can be validated. This of course means adopting a particular philosophical approach (in this case a variation of Popper) and requires (i) a degree of intellectual vigor in government that is not likely any time soon and (ii) fails to appreciate the messy bottom up approach implied by taking a complexity science approach to the problem.
Now I don’t intend to devote anytime to the second theme, I think it defeats itself by its nature.”
I hardly know where to begin in discussing this paragraph, since I think that so much of it is over-stated and misleading, so I guess I’ll just begin at the beginning and work my way through. First, I don’t know of any approach advocated in the actkm discussion that states flatly that any kind of approach requires a careful definition of KM, or that an individual project can’t be good KM even though it doesn’t use a clear definition of the subject. I, have, of course, contended very often that clear definitions of KM, not necessarily the same, are needed to have cumulative progress in KM. I’ve argued that point in two articles, here and here, and thus far, at least, I don’t think that Dave has been successful in countering them.
Second, I don’t know of anyone who in the recent actkm exchange has said that specific criteria are necessary for validation. Don’t get me wrong, I, personally, frequently advocate knowledge claim evaluation, the process of eliminating errors through criticisms, tests, and evaluations, as a necessary step in arriving at knowledge. In some of my writings, I’ve even specified a framework for evaluation that could be interpreted as involving criteria. However, I certainly have never claimed that either criteria, or my particular fair critical comparison framework are necessary for selecting among competing views or solutions to problems, I.e. for knowledge claim evaluation. Lastly, for some years now I haven’t written about “validating” knowledge claims. I used to talk that way during the 1990s, but close to six years ago I realized that the idea that generalizations can never be verified by a finite number of instances implied that general knowledge could not be “validated ” by its performance, but could only survive our experience without being refuted.
Third, nor is it true that accepting that clear definitions of KM are important, and that knowledge claim evaluation is a necessary stage in making new knowledge commits one to adopting a particular philosophical approach such as a variation of Popper’s approach. Of course, as Dave well knows, I do use a variant of Popper’s approach, but others might, and, in fact do, use a variant of Peirce’s approach, or a variant of Mill’s approach, or a variant of any one of many other approaches to knowledge claim evaluation. Indeed, one might even invent one’s own approach. The point is that practicing knowledge claim evaluation in an explicit way, does not require commitment to a particular person’s philosophy. One is quite free to draw from any number of sources and to synthesize one’s own theory of knowledge claim evaluation in order to practice it.
Fourth, in asserting that the second theme requires “a degree of intellectual vigor . . . “ (should that have been “rigor”?) in Government that is not likely any time soon, I think Dave is assuming that knowledge claim evaluation always requires formal comparison of alternatives, but this is true only in unusual instances where time is available for a fair critical comparison, and where the risk of error in decision making is great enough to warrant the time and expense it takes to be rigorous.
Fifth, there is nothing about the second theme that implies its opposition to “complexity science,” or to “messy bottom up” approaches to problems. Its only opposition is to those “complexity science” studies that gloss over Knowledge Claim Evaluation and don’t make explicit how it is actually practiced in organizations; since these studies are certainly not instances of “science,” complex or otherwise.
Finally, one can easily say that the ‘second theme,” is self-defeating by its very nature and leave it at that. But without showing why it is self-defeating, there is very little that one can say about such judgments except to register disagreement.
Tags: Complexity · Epistemology/Ontology/Value Theory · Knowledge Making · Knowledge Management
In a recent post entitled “The Emperor’s Chess Board: Pt 1”, Dave challenged “the concept of centralisation of a government knowledge function (I will qualify this a bit in a future post), arguing that it would manifestly lead to failure to achieve the key goals of making a nation more secure.”
Before I consider Dave’s primary argument, I want to point out two assumptions that I think pervade the above post, as well as two others Dave posted on this theme, at the time of this writing. First, I think Dave assumes that the government knowledge function and the government KM function are one and the same. I don’t agree. The knowledge function covers the activities of problem seeking, problem recognition, and problem formulation, making discovering, creating, and/or producing new knowledge, and integrating both new and old knowledge. These activities occur all over Government; they always will; and no one is proposing centralizing them.
Second, I also think that Dave is assuming that any kind of central organizing function for knowledge processing in National Governments is inimical to self-organization and adaptiveness in Government, and he seems to continually contrast stifling centralization with the autonomy and creativity of self-organization. I don’t agree with this sort of dichotomy. I think it’s possible to have central organizations that facilitate self-organization and distributed knowledge processing. And I also think that having such institutions in Government, and especially in KM are both necessary and possible for the further development of Democracy.
Dave’s primary argument that a centralized KM function will lead to failures in national security is based on the idea that the justification of such a function is a) past failures have resulted from the fact that we have not been able to “connect the dots”; b) to connect the dots we need to have “bigger and bigger databases, with more search algorithms,” centralized functions, standardized procedures, and a KM Czar, and c) these measures will ensure that no future errors will occur. He reasons, correctly, that there is a numbers, or unmanageable combinatorial, explosion problem here that makes it impossible to connect all dots, and then ends with an effective rhetorical flourish, especially in the context of National Governmental KM in the United States:
“How many dots are there in a human system? How many possible patterns? OK hindsight is a wonderful thing as the significant dots and the linkages are now visible, but in respect of foresight? Forget it. Remember Lincoln? He said in his second annual message to Congress in 1862 As our case is new, so we must think anew, and act anew. We must disenthrall ourselves, and then we shall save our country. Never a truer word more greatly ignored in government and most certainly ignored by those presenting the same old tired solutions of centralised knowledge management?”
I agree with this conclusion of Dave’s, and I supported it in an actkm post at a number of points and especially with these words:
“The most serious failure of KM in Government is not the failure of “information integration,” though I don’t mean to minimize the seriousness of that failure; but the more serious failure is the failure to create an ecology of rationality throughout our national governments that enables us “think anew and act anew.” That is the real generalized solution to the “connecting the dots” problem. For the problem of “connecting the dots,” is not the mechanical one of generating all the possible patterns that arise from a series of data nodes. Rather, it is the problem of being able to invent new theories and rise above and beyond the mere data represented by the dots, or the patterns that we impose on those dots with algorithms of one sort or another. No doubt that such analyses and such algorithms can help us in analysis, but ultimately the patterns we arrive at are our conjectures and they are theoretical constructs that go beyond the data.
“So, we have to learn about and implement the kind of ecology that can best enable our knowledge workers to arrive at such theoretical constructs more effectively and to evaluate and select among them more effectively. This is the most important task of KM, and I think it is the biggest failure of KM in our National Governments.”
However, even though I agree with Dave’s argument about the impossibility of “connecting the dots,” with brute force database and search methods, I don’t think this is an effective argument against the idea that there should be a National KM Center. There is an entirely different argument for a National KM Center than the one Dave criticized in his “Empire” posts. It is outlined here, here, and here. And it is based on the idea that a National KM Center organized in the way I proposed, would enable decentralized Knowledge Management, support distributed problem solving, self-organization, and “connecting the dots,” by producing an ecology that facilitates creating new ideas that both interpret “the dots and their connections” in new ways that are closer to the truth, and also go above and beyond them to provide at least the kind of foresight that it is possible to achieve in human complex systems.
Such a Center would enable and support KM throughout the Government, enhance its adaptiveness through the impact of better KM on knowledge processing, while also making it accountable to legislative fiduciaries. And its operation would have nothing to do with the idea of “connecting the dots” by using the brute force approach Dave has argued against.
Tags: Complexity · Epistemology/Ontology/Value Theory · KM Techniques · Knowledge Making · Knowledge Management
August 6th, 2008 · Comments Off on KM 2.0 and Knowledge Management: Part Three, More Skepticism and Okimoto’s Conceptualization

Until the late spring of 2007, discussion about KM 2.0 had raised a number of issues and themes including:
— KM 2.0 is KM which utilizes Web/Enterprise 2.0 tools to enable greater connectivity and self organization in one’s enterprise;
— Before the introduction of Web/Enterprise 2.0 tools KM had been a command-and-control-oriented approach, but KM 2.0 introduces an entirely new orientation focusing on self-organization and community;
— KM 2.0 social media tools are used in the service of creating an ecology that improves connectivity, resulting in building relationships and trust, resulting in better communications and knowledge sharing;
— Is KM 2.0 the use of the new social media tools in an enterprise? That is, is KM 2.0 equivalent to Enterprise 2.0? Or is KM 2.0 a more broadly social activity that simply uses the new tools as an instrument?
During the remainder of 2007, the discussion of these themes continued. A good example is provided by Paula Thornton in a post entitled “Knowledge Doesn’t Want to Be Managed:”
“In deference to Bill Ives’ recent post, 2.0 and KM are not in the same galaxy. The fundamental potential of 2.0 is emergent (referred to in the discussion at the Web 2.0 Expo in April). Knowledge Management is and has always been a misnomer: knowledge cannot be managed.”
That is, KM 2.0 is nonsense, because KM is about control of knowledge which is nonsense; while 2.0 is about enhancing “Your ability to think and act,” and also about “emergent” knowledge.
In September of 2007, Jennifer Okimoto, of IBM Global Services, made public a slide deck entitled “Industry Trends: the evolution of knowledge management (KM 1.0 vs. KM 2.0). The slide deck makes the far from innovative point that KM is about creating the perfect balance among people, process, and technology. It proceeds to make the more important point that traditional, KM 1.0, and KM 2.0 methods co-exist since “as new sources and methods to share knowledge appear, none of the old disappear.” Jennifer Okimoto then presents IBM’s view of the evolution of KM and collaboration in a two column, 11 row table, full of dichotomies. The left column is labeled “KM and Collaboration in the past,” and the right “KM and Collaboration moving forward.” Here are the 11 dichotomies:
1) “KM and collaboration is extra work” vs. “Collaborative work is what work is”
2) “KM and collaboration are sets of tools” vs. “Collaboration is co-authoring the outcome”
3) “I work by myself” vs. “I am immersed in the conversation of the workplace”
4) “People directories provide contact information” vs. “Dynamic profiles reflect what I do, with whom, and how well I do it”
5) “Work happens in unannounced groups” vs. “Work happens publicly where everyone participates”
6) “Content is protected” vs. “Content is fluid and is developed through participation”
7) “Searches for content and experts are unrelated” vs. “Experts lead to content, content leads to experts”
8) “My value to the company is based on my deliverables” vs. “I am a professional whose value is based both on my deliverables and my reputation”
9) “Customers are interesting” vs. “I depend on customers for feedback”
10) “The online experience is a Conversation with text and data” vs. “Collaborative work and Conversation with data are equally important”
11) “Targets increased productivity” vs. “Provides a platform for innovation”
These dichotomies are all very interesting, but the question is do they describe reality or are they merely a “straw man,” even a myth about what the characteristics of KM and Collaboration were and what they will be moving forward. I’m afraid I come down on the side of myth, a mere story in the pejorative sense, a consultant’s device used to brief and persuade prospective clients rather than an attempt to develop a serious characterization of what KM has been like in the past, and what it will be like moving forward. Thus, nearly every one of the left side of these dichotomies either has little to with KM or alternatively describes KM inaccurately. That is, the left side of dichotomies 3-11 have nothing directly to do with KM prior to September of 2007 in the sense they are part of any formal view of KM that is current in the KM literature. Also, KM has not been viewed as a “tool” by a majority of KM practitioners, for at least a decade, and as far as I know collaboration has never been viewed as a tool in KM, but as a very important social activity.
It is true that KM has been perceived as “extra work,” but this perception is related to a view of what KM is, that is highly questionable. That is, KM, viewed as an activity aimed at enhancing knowledge processing is always extra work, and remains extra work even if web 2.0 tools are provided through a KM intervention, however, knowledge processing is not necessarily extra work. It is what people do when they have to solve problems. It should be part of their daily work, and certainly can be, and often is embedded in it. Collaboration is also often involved in problem solving, and when it is, it is not extra work, but, it too, is part of problem solving.
In any event, even those who confuse KM and knowledge processing and use the two terms interchangeably have been attempting to perform KM in such a way that knowledge processing is embedded in work. That is the whole idea in back of “just-in-time” KM, which pre-dates “KM 2.0” by at least 5 years.
When we look at the right-hand side of the 11 dichotomies we, again encounter the question of the relationship of KM to dichotomies 3-10. That is, perhaps these do describe KM 2.0, but why should we believe that? What is the connection between some explicit notion of KM and the right-hand side of dichotomies 3-10. To be even more specific, anyone can say they are characterizing KM going forward and then specify some list of characteristics that is supposed to describe KM 2.0, but why and how are these characteristics related to the underlying idea of KM. I’m afraid that’s not clear in the slide set. In fact, there is no underlying idea of KM expressed in the slide set, which is why it is so hard to understand what either the left or right-hand sides of these dichotomies have to do with KM.
Nor is the relationship of the right-hand side of dichotomies one and two to KM clear. Both dichotomies refer explicitly to collaboration, but, at least on the right-hand side, not to KM. So what is the significance of this? Is Jennifer Okimoto saying that KM 2.0 is really “collaboration?” If so, this is clearly just a misuse of language.
Finally, dichotomy 11 is posed as: “Targets increased productivity” vs. “Provides a platform for innovation.” Presumably this is to make the claim that KM used to be about increasing productivity, but going forward will be about providing a platform for innovation. However, there was never universal agreement that KM was about increasing productivity, and the idea that one of the primary purposes of KM is to enhance innovation has been mentioned in KM from the beginning, and had gained wide recognition by the year 2000.
A final slide in the presentation is about “driving critical people connections.” and identifies:
— “Mobilizing and mining the collective brain” (Extended enterprise, structured)
— “Global water cooler” (Extended enterprise, unstructured)
— “Helping hand in collaboration,” (Group, structured) and — “Targeted yet free flowing collaboration” (Group, unstructured)
While this is perhaps a useful typology, it doesn’t clearly distinguish KM 1.0 from KM 2.0, from my point of view, though clearly it does if one were to assume the validity of the characterizations of KM 1.0 and 2.0 provided earlier.
In sum, Jennifer Okimoto’s slides provide a perspective on the KM 1.0/2.0 issue that goes far beyond the previous discussions of the subject, and for the reasons I’ve given above is a bridge much too far, because it is based on highly questionable characterizations of both conjectured states of KM. In Part Four, I’ll continue my discussion of views of KM 2.0 developed in 2007
Tags: Complexity · KM 2.0 · KM Software Tools · Knowledge Integration · Knowledge Making · Knowledge Management
